

I cannot code. Not properly, anyway.
And yet I built a bot that runs 24/7 on Hyperliquid, trades autonomously, and was created almost entirely by describing the idea in plain English to AI.
That is the wild part here. Not just the bot itself, but the process.
The real edge was never “AI writes code now, wow.” The real edge was spotting a market inefficiency, forming a hypothesis about why it existed, validating that with research, and then using AI to turn that idea into working software.
This is for information and entertainment only, not financial advice. Always do your own research.
Table of Contents
- The important bit is not the bot. It is the process.
- Why new DeFi markets are often incredibly inefficient
- The specific market inefficiency I found on Hyperliquid
- Bitcoin was moving normally. The prediction market was not.
- Research first, then automation
- What the bot actually did
- Why this worked so well at the start
- What made these Hyperliquid markets especially attractive
- The size of the mispricing was bigger than most people realize
- AI has made bot building dramatically more accessible
- Why copying someone else’s bot is the wrong lesson
- Risk management: autonomous does not mean unattended
- The real takeaway
- FAQ
The important bit is not the bot. It is the process.
There is a tendency to focus on the end result and miss the only part that actually matters.
Here is the workflow I used:
- I noticed a newly launched market behaving oddly.
- I watched it for a day or two.
- I formed a hypothesis about the mispricing.
- I used AI to help research whether the hypothesis was real.
- I used AI again to build a bot around that research.
- I tested it, iterated on it, and let it run.
That entire loop happened in natural language. No hardcore programming background required. I basically explained the idea like a normal person, refined it through back-and-forth prompts, and kept tightening the logic until the thing actually worked.
This is why AI changes who gets to build software. If you can think clearly enough to identify an opportunity, you can often get a machine to help you implement it.

Why new DeFi markets are often incredibly inefficient
The opportunity came from a simple observation: new markets are usually inefficient at launch.
That is true across DeFi, and it is especially true when a product is new, thinly traded, or not yet deeply arbitraged by sophisticated participants.
Hyperliquid has been successful because its core markets gained serious liquidity and became efficient enough for real traders to rely on. But newer products on the same platform do not start out that way.
In general, the signs of inefficiency are pretty straightforward:
- Low open interest often means fewer participants and weaker price discovery.
- Modest daily volume can mean slower arbitrage and wider mispricings.
- No volume at all is not useful, because there is no real edge if nobody is trading.
You need some activity, but not so much that every discrepancy gets instantly cleaned up.
This is also where people sometimes go wrong. They think “inefficient” means “easy money.” It does not. If the market is dead, there is nothing to trade against. If it is active but sloppy, that is where things get interesting.
And if you are comparing automated systems with curated trade ideas, it is worth understanding the trade-off between fully self-built bots and external guidance. A lot of traders still use tools like best crypto signals to identify opportunities and validate setups before automating anything. That can be a much safer bridge than jumping straight into live bot trading with no framework at all.
The specific market inefficiency I found on Hyperliquid
The strategy was built around Hyperliquid’s newer prediction-style markets, specifically the up-or-down outcome markets tied to Bitcoin.
These are simple contracts. You are betting on whether something happens by a certain time. For example:
- Will Bitcoin be above a specific price tomorrow?
- Will it be lower?
The pricing works like a probability market:
- If “Yes” trades at 65 cents, the market is implying roughly a 65% chance of that outcome.
- If “No” trades at 35 cents, it implies roughly a 35% chance.
- If your side is correct at settlement, that share becomes worth $1.
- If it is wrong, it becomes worth $0.
Simple enough.
The issue was that this market seemed to react far too aggressively to small early moves in Bitcoin itself.
That was the clue.
Bitcoin was moving normally. The prediction market was not.
I was looking at two things together:
- The actual Bitcoin price
- The 24-hour prediction market on whether Bitcoin would finish higher or lower the next day
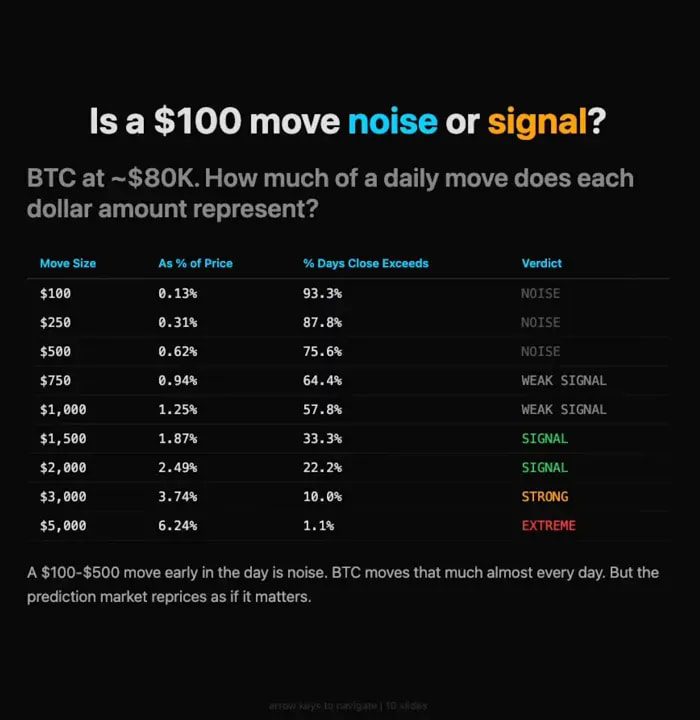
Bitcoin is always volatile. A move of $100 or $200 or even $500 is not some shocking event in isolation. It can happen all the time without telling you much about where price will end the day.
But the prediction market was swinging around as if those moves were highly informative.
At one point, the market implied about a 55% chance that Bitcoin would be higher the next day. A few hours later, it had swung down near 30%. Then it bounced back toward 50%, then dropped again.
That kind of movement in the probability market looked excessive relative to what Bitcoin itself had actually done.
Put differently, the market was acting as if a fairly ordinary short-term BTC move had suddenly made tomorrow’s outcome much more predictable than it really was.
That did not feel right. So the next question was obvious: was I seeing a real inefficiency, or was I just misunderstanding Bitcoin’s volatility?
Research first, then automation
This is where the process matters.
I did not just trust the intuition and fire off a bot. I used AI to help test the idea.
The question was simple: if Bitcoin moves a few hundred dollars early in a 24-hour period, how much should that actually change the probability of where it ends up by the next day?
The answer, based on the research, was: not much.
Early moves inside the first few hours were largely noise unless they were unusually large. In a 24-hour market, what happens in the first four hours often does not tell you much about what happens in the next twenty.
That makes intuitive sense. A full day is a long time in crypto. Plenty can happen after the initial move.
So the inefficiency became clearer:
- The market might price a contract as if there were a 65% chance of an outcome.
- The research suggested the real probability was more like 55% to 60%.
- That gap was the edge.
Not a gigantic edge on any single trade. But a repeatable one.
What the bot actually did
Once the research was solid enough, I handed the logic to AI and told it to build the bot.
Again, this was done in natural language. The prompt was not elegant computer science. It was basically:
- Here is the research
- Here is the inefficiency
- Monitor Bitcoin and the market price
- Trade when the market meaningfully deviates from fair value
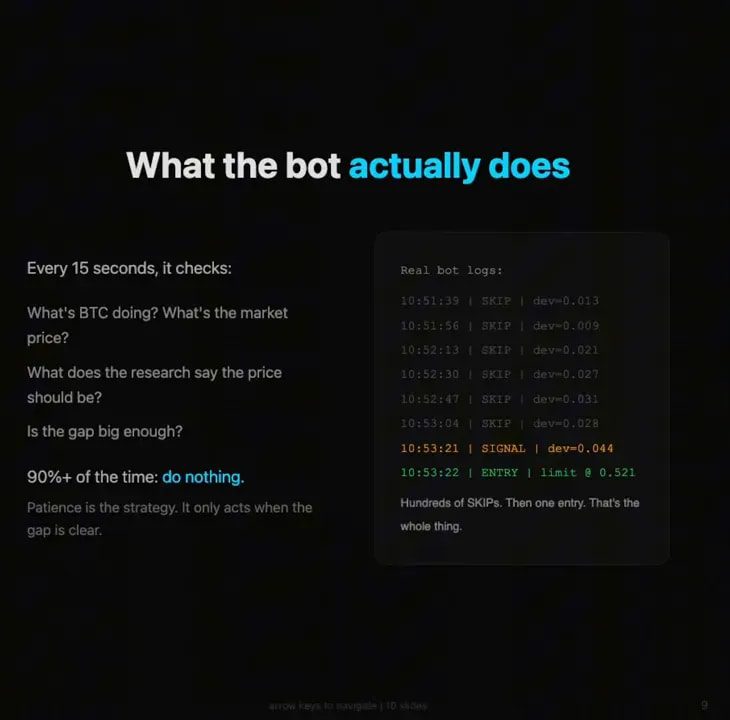
The resulting system checked conditions every 15 seconds.
It was watching things like:
- Bitcoin price movement
- The current implied probability in the prediction market
- Whether the market was overreacting relative to the underlying research model
Most of the time, it did nothing.
That is important. Good bots do not need to be busy all the time. They need to be selective.
Then, every so often, it would detect that the contract price was off by a few cents relative to what it “should” be. It would enter a position, wait for mean reversion or repricing, and close when the market came back toward fair value.
Sometimes the market stayed wrong for longer than expected. Some trades went underwater. That is normal. So there were stop losses and risk controls built in as well.
But the principle was simple: trade temporary mispricings, not directionally “predict Bitcoin.”
Why this worked so well at the start
The bot reportedly made 50% on day one.
That is not a promise. It is definitely not a sustainable benchmark to anchor on. It is a reflection of how sloppy these new markets can be right at launch.
Early is the edge.
The same market was already more efficient the next day than it had been the day before. That is exactly what you would expect once more people notice the discrepancy and start fading it.
This is the pattern worth paying attention to:
- New on-chain products launch
- Liquidity is still developing
- Pricing models are noisy
- Users and bots begin arbitraging the obvious mistakes
- The edge compresses fast
That is why copying someone else’s old code is usually a terrible idea in markets like this. By the time a strategy is circulating widely, the easy version of the edge is often gone.
If you are not building your own systems, another practical route is combining discretionary market analysis with external trade frameworks. Many traders do this by following structured alerts or using crypto signals for maximum profit while they learn how market inefficiencies behave in real time. The key is not blind copying. It is understanding why the setup exists.
What made these Hyperliquid markets especially attractive
There were three reasons this setup stood out.
1. More HIP-4 markets are likely coming
If one newly launched market can be inefficient, the odds are good that future ones will be too.
Today there may be only a couple of these markets. In a month there might be several. In six months there could be many more. Whenever a platform rolls out a fresh product category, there is usually a window where pricing quality lags behind participation.
2. Fees were effectively free
That matters a lot for small mean-reversion trades.
If your edge is a few cents on a contract, fees can kill the strategy. If fees are minimal or zero, it becomes much easier to exploit these short-lived dislocations.
3. There may be future reward incentives
No guarantees, obviously.
But Hyperliquid still has a large portion of token supply earmarked for community or future rewards. If that gets distributed instead of burned, it is reasonable to think active users of newer or more innovative product lines could be rewarded.
The logic is straightforward: protocols often want to incentivize the behaviors that deepen usage across the ecosystem, not just concentrate activity in one legacy product. So people using prediction markets, HyperEVM products, or newer trading rails may be in a better position than those who only use the most established features.
The size of the mispricing was bigger than most people realize
One of the more striking observations was this:
Bitcoin itself traded in about a 1.6% range, while the associated HIP-4 market traded in roughly a 109% range.
That is a massive difference in behavior.
Of course, a prediction contract can move more dramatically in percentage terms than the underlying asset. But when that magnitude of variance shows up repeatedly without equivalent information flow, it is usually a sign that the market structure is immature.
And immature structure is where people with good process can extract value.
AI has made bot building dramatically more accessible
This is the bigger story behind the trade itself.
You no longer need to be a professional developer to create functional software. You do need to think clearly. You do need to break problems into steps. And you do need to test aggressively.
But today, non-technical people can do things that would have been completely unrealistic not long ago.
You can:
- Describe a strategy in plain English
- Ask AI to structure the logic
- Connect APIs and market data
- Build basic execution rules
- Iterate until the system behaves correctly
For a lot of traders, that is a huge unlock.
You do not even necessarily need a VPS to start. A local machine can be enough for testing and even for running certain lightweight strategies, depending on the setup. The point is that the barrier to entry has collapsed.

Why copying someone else’s bot is the wrong lesson
If there is one thing to avoid taking from this, it is the idea that the answer is to grab somebody else’s code and let it run unsupervised.
That is how accounts get wrecked.
Especially in inefficient markets, conditions change fast. The exact behavior you are exploiting today can disappear tomorrow. A strategy that worked beautifully in a soft launch environment can start bleeding once market participants adapt.
This is why iteration matters more than code ownership.
The edge was not in the syntax. The edge was in:
- Noticing the discrepancy
- Testing whether it was statistically meaningful
- Building logic around that finding
- Updating it as market conditions evolved
That is a much more durable lesson than any single bot template.
Risk management: autonomous does not mean unattended
This part matters more than the flashy headline.
A bot can be autonomous and still require human supervision.
In fact, it absolutely should.
Even with stop losses, fail-safes, and sensible execution rules, a trading bot needs oversight. Market structure can shift. Exchange behavior can change. Data feeds can glitch. Liquidity can dry up. The “edge” can disappear while your bot is still trading as if nothing happened.
If you leave an unsupervised bot running on an inefficient market for days, there is a very real chance you come back to an empty account.
At minimum, automated trading systems need:
- Position sizing limits
- Stop losses
- Sanity checks on market data
- Execution fail-safes
- Regular manual review
This is also why many traders prefer a middle ground before going fully automated. They use structured analysis, alerts, or crypto signals for trading to help evaluate conditions while keeping final execution and oversight in human hands. For a lot of people, that is the more sensible path.

The real takeaway
The most exciting part of this entire exercise is not that one bot worked on one market for one day.
It is that the workflow is now open to far more people than before.
If you can spot an inefficiency, articulate a hypothesis, validate it with data, and iterate with AI, you can build surprisingly powerful tools without being a traditional programmer.
And in crypto, where new products launch constantly and market structure is often still forming, that matters a lot.
There will be more weird markets. More temporary dislocations. More products that go live before pricing is truly efficient.
The people who do well will not just be “the best coders.” They will be the people who notice what others ignore, ask the right questions, and move early enough to capture the edge before the market grows up.
FAQ
Can someone really build a crypto trading bot without knowing how to code?
Yes, at least for simpler systems. AI tools can help translate plain-English strategy ideas into working code. The difficult part is not just generating code. It is having a valid market hypothesis, testing it properly, and managing risk once the bot is live.
What was the edge in this Hyperliquid strategy?
The edge came from a prediction market that appeared to overreact to small early Bitcoin price moves. Research suggested those early moves were mostly noise, so the market-implied probabilities were sometimes meaningfully off from fair value.
Why are new DeFi markets often inefficient?
New markets usually start with lower liquidity, less participation, and fewer arbitrageurs. That means price discovery is weaker and temporary mispricings are more common, especially during the early launch phase.
How often did the bot trade?
The bot checked conditions every 15 seconds, but most of the time it did nothing. It only entered trades when it detected a meaningful discrepancy between the prediction market price and the fair value implied by the research.
Does autonomous trading mean you can leave the bot alone?
No. Even autonomous bots need supervision. Market conditions change quickly, data can fail, and an inefficiency can disappear without warning. Stop losses and fail-safes help, but they do not remove the need for human oversight.
Is copying someone else’s trading bot a good idea?
Usually not. In fast-moving and inefficient markets, copied strategies can become outdated almost immediately. The more valuable skill is understanding how to identify, validate, and adapt to an edge rather than relying on static code.

{kind=link}